InputFormat 和 OutputFormat
Hadoop的 Mapreduce 模型如今已深入人心。而当你学会写WordCount 之后,就会对这个简洁的计算模型产生更多的疑问。
数据文件从 hdfs 进入 Mapper 实例的 map 方法之前,都经历了那些过程?
数据文件在统计结束之后,怎么写入 hdfs ? 可以使用自定义的文件格式输出吗?
是时候把视线转向 MapReduce 之外,看看Hadoop是如何为MapReduce计算做准备和善后工作的了。
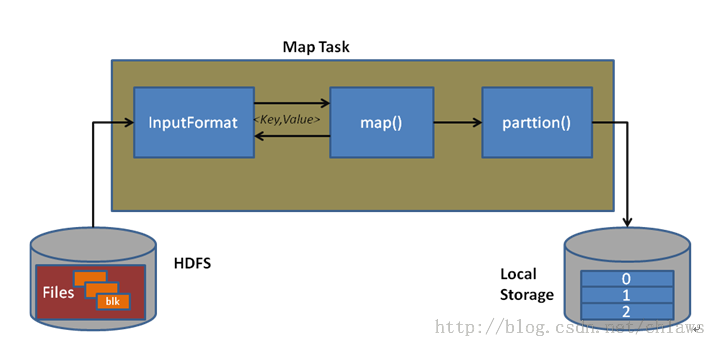
InputFormat
在WordCount里面你会用 FileInputFormat.addInputFormat(job, new Path(...)) 来声明数据文件的来源。
InputFormat 是一个java接口, 而FileInputFormat正是一个实现了该接口的类。接口中有两个函数, 分别是
InputSplit[] getSplits(JobConf job, int numSplits) throws IOException;
与
RecordReader<K, V> getRecordReader(InputSplit split,
JobConf job,
Reporter reporter) throws IOException;
源码的注释里这样说,InputFormat 为 MapReduce框架做了三件小事:
- 检查文件的类型
- 将文件分割成 逻辑分块(
InputSplit), 每个分块由一个Mapper实例来计算。 - 提供一个
RecordReader实例,用以从逻辑分块中读取一条记录,交给Mapper 实例。
代码本身就是很好的注释,指明了 Hadoop 读取文件所需的三个最基本的类: InputFormat, InputSplit, RecordReader。
InputSplit vs Hdfs Block
hdfs 对其存储的大文件进行分块( block ),而MapReduce 时 所用的逻辑分块 InputSplit 和 物理分块 并非绝对的一一对应。分片长度,根据程序配置(或者环境变量)中的mapreduce.input.fileinputformat.split.minsize 与 FileStatus.getBlockSize,numSplits 计算出来。
如果关注一下 getSplits的源码,就会发现,一个逻辑分块InputSplit可以包含一个或多个物理分块Block, 而逻辑分块的数量,也就是 MapTask 的数量。
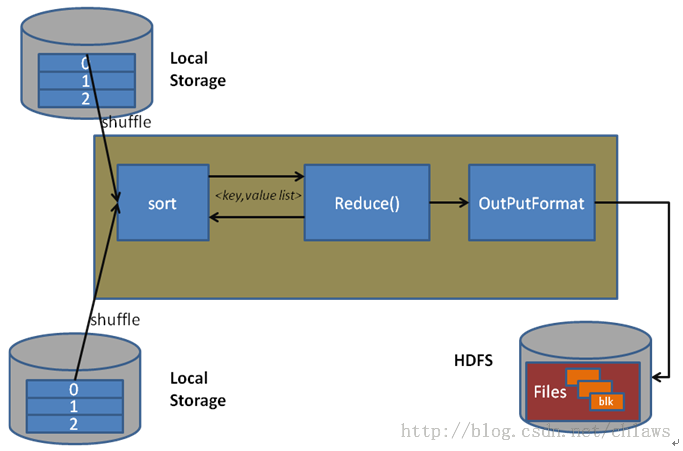
OutputFormat
很多情况下我希望把MapReduce的计算结果持久化,而非简单地打印到屏幕上。这时 OutputFormat 家族就登场了。源码注释里这样说:OutputFormat 为MapReduce 任务提供如下的功能
- 检查输出环境,比如输出文件的路径是否已经存在
- 实现了
RecordWriter类。
虚类RecordWriter指定了两个接口函数, write 和 close ,而RecordWriter的子类,最终完成了写数据的任务。
OutputFormat的众多子类, 提供了丰富的文件格式,比如:
FileOutputFormat(实现OutputFormat接口)—— 所有OutputFormats的基类
- MapFileOutputFormat —— 一种使用部分索引键的格式
- SequenceFileOutputFormat —— 二进制键值数据的压缩格式
- SequenceFileAsBinaryOutputFormat —— 原生二进制数据的压缩格式
TextOutputFormat —— 以行分隔、包含制表符定界的键值对的文本文件格式
MultipleOutputFormat —— 使用键值对参数写入文件的抽象类 - MultipleTextOutputFormat —— 输出多个以标准行分割、制表符定界格式的文件 - MultipleSequenceFileOutputFormat —— 输出多个压缩格式的文件
最后用两张图直观地感受一下 InputFormat 和 OutputFormat 在 MApReduce 框架中发挥的作用吧。
参考